MaxCompute创建基于python的UDF函数并引用第三方包,例如UDF中使用pandas包及其依赖的其他第三方包。
最终实现效果
前提条件
- MaxCompute集群已安装Python环境,该案例中Python是3.7版本
- 已安装并配置MaxCompute客户端
使用pandas包
由于集群中Python是3.7版本,所以使用pandas包版本也必须使用cp37,该案例以pandas 1.1.5版本为基础。
-
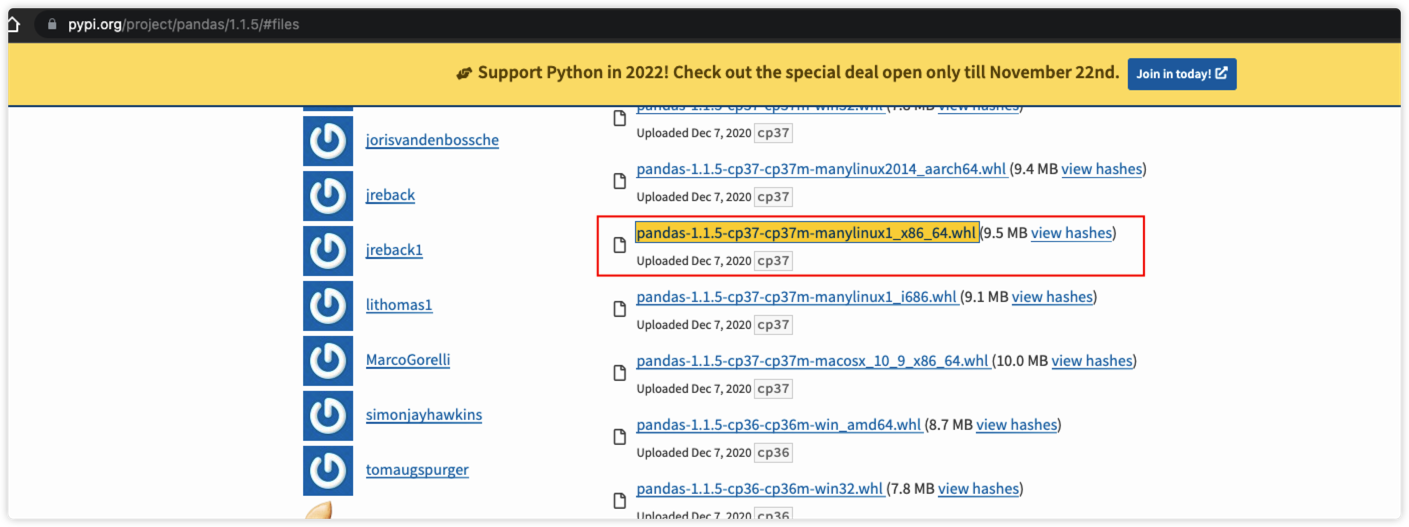
在PyPI页面的Release history区域找到1.1.5版本,单击Download files后找到文件名为pandas-1.1.5-cp37-cp37m-manylinux1_x86_64.whl的pandas包进行下载。
-
修改下载的pandas包后缀为zip格式
-
通过MaxCompute客户端上传pandas包至MaxCompute项目空间,如果客户端使用的是本地终端,pandas-1.1.5-cp37-cp37m-manylinux1_x86_64.zip也可以为绝对路径。
1
odpscmd -e "use abi_ods_dev; add archive pandas-1.1.5-cp37-cp37m-manylinux1_x86_64.zip -f"
-
在DataWorks的
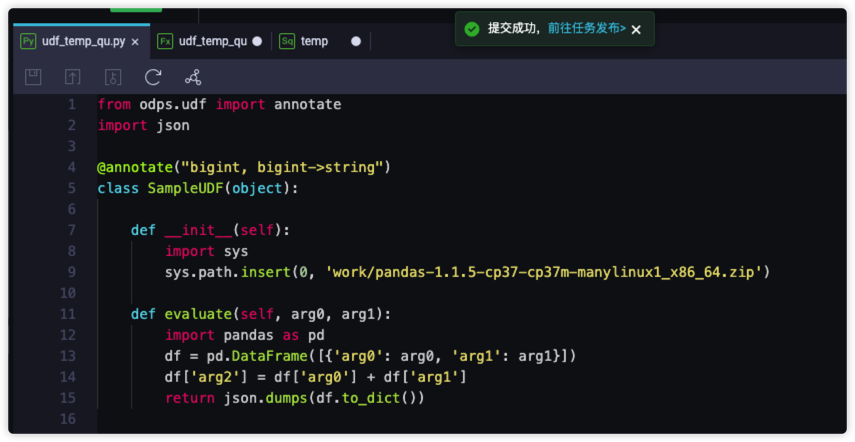
业务流程/你的业务流程名称/MaxCompute/资源/目录下创建Python脚本,此处以udf_temp_qu.py为例,详细的UDF代码结构请参见Python 3 UDF1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16from odps.udf import annotate
import json
class SampleUDF(object):
def __init__(self):
import sys
sys.path.insert(0, 'work/pandas-1.1.5-cp37-cp37m-manylinux1_x86_64.zip')
def evaluate(self, arg0, arg1):
import pandas as pd
df = pd.DataFrame([{'arg0': arg0, 'arg1': arg1}])
df['arg2'] = df['arg0'] + df['arg1']
return json.dumps(df.to_dict()) -
保存udf_temp_qu.py并提交
-
在DataWorks的
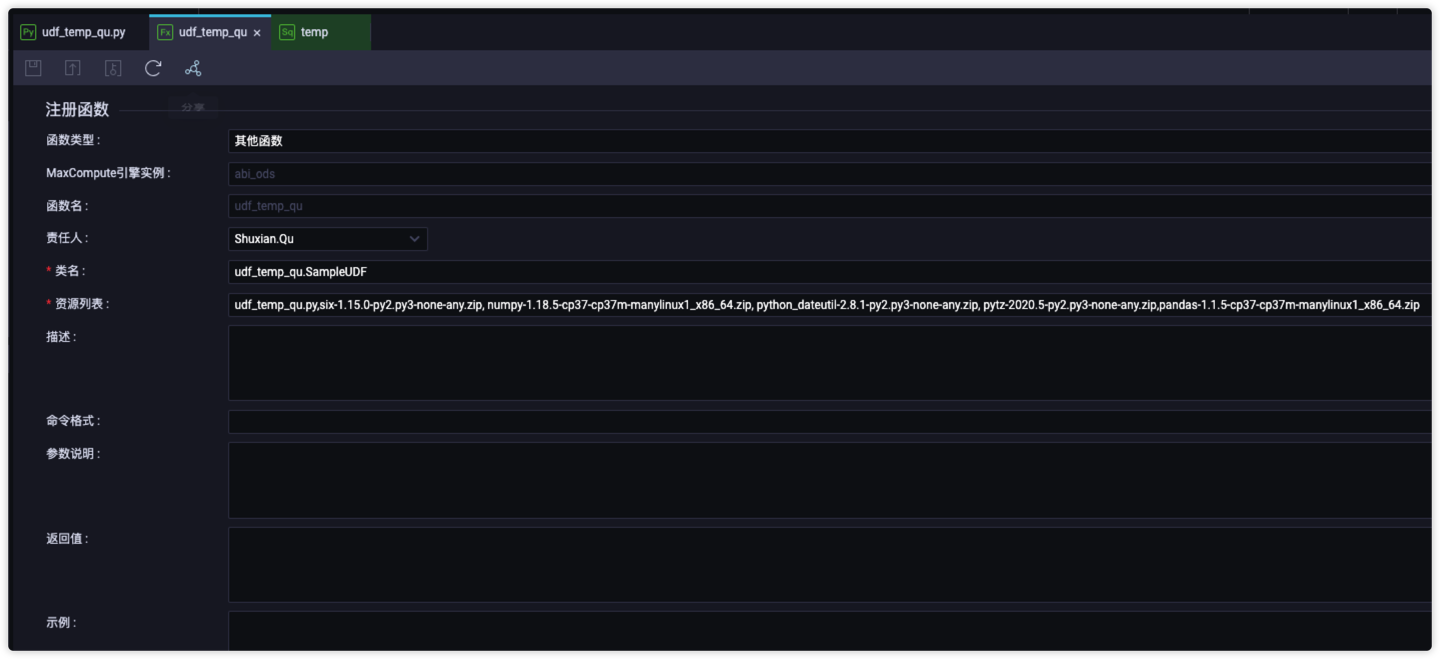
业务流程/你的业务流程名称/MaxCompute/函数/目录下创建UDF函数,此处以udf_temp_qu为例,资源列表中需要引用第5步的资源名称和pandas的资源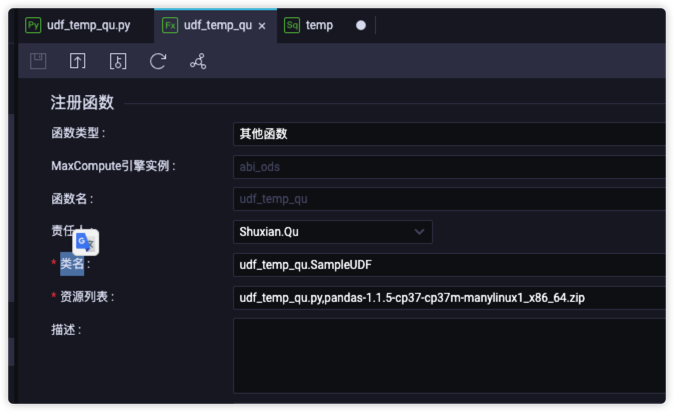
-
保存udf_temp_qu并提交
-
测试UDF函数
1
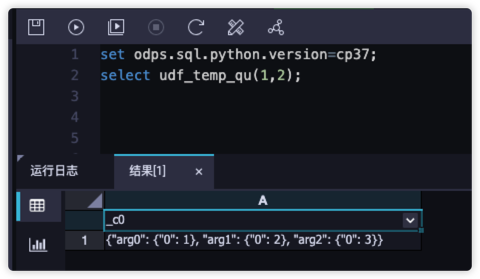
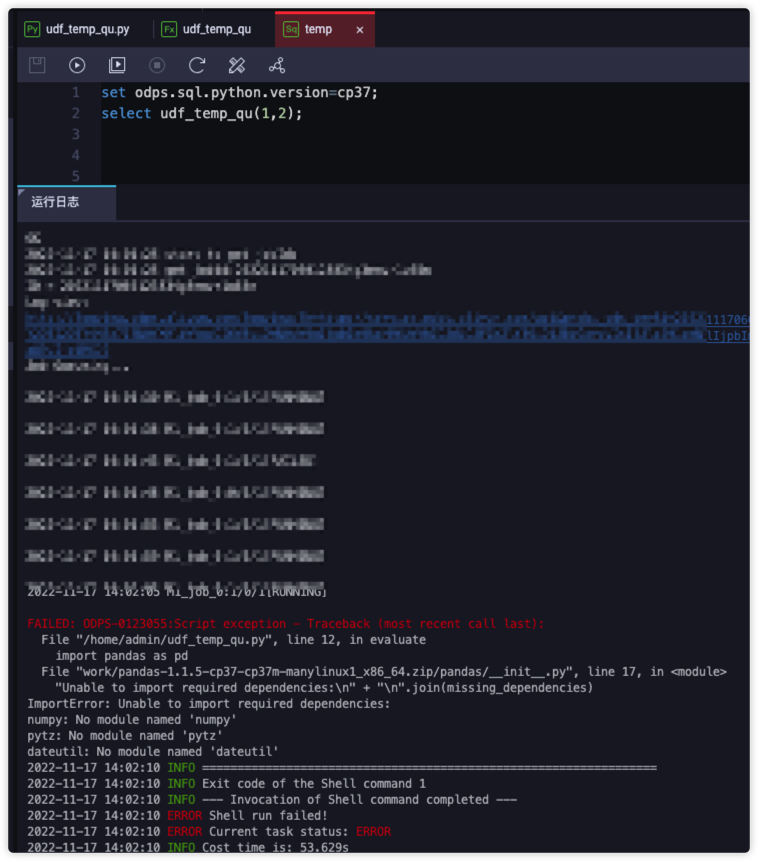
2set odps.sql.python.version=cp37;
select udf_temp_qu(1,2);从测试结果来看,提示pandas包依赖的其他第三方包缺失、例如numpy等
-
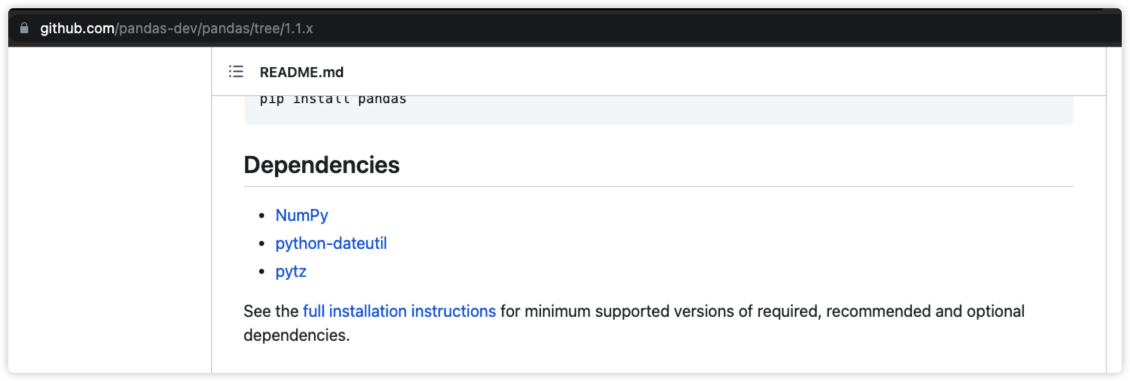
到pandas的官方GitHub1.1.x文档可以看到,pandas依赖了3个第三方包,然后下载对应PyPI上下载对应版本的whl包
-
将新下载的第三方包重复执行第一步到第七步
-
大功告成
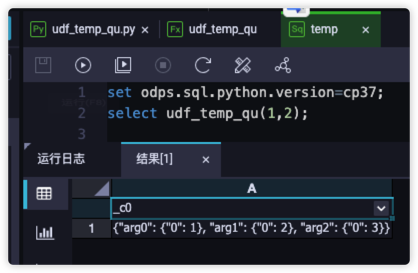
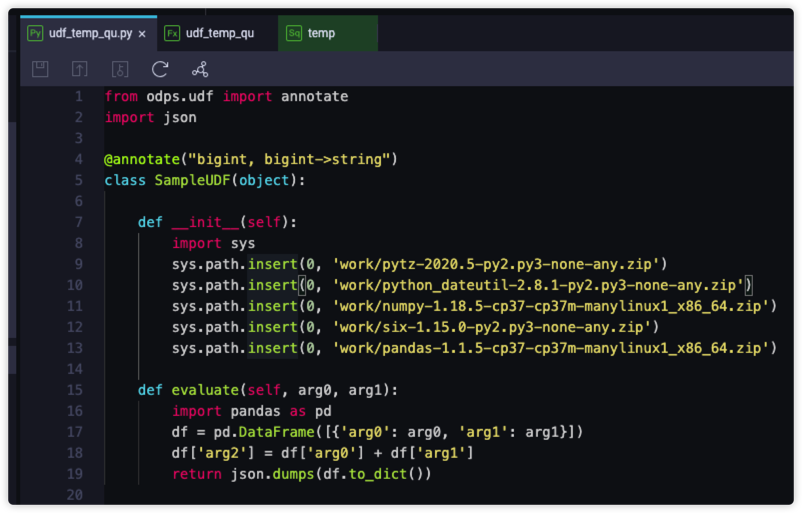
最后再看一下资源和函数的配置
 |
 |
|---|

